Lab 1: CMake and Toolchain
Before You Begin
Take some time to review the Lab Guidance before beginning on these labs. If you’re using the labs to populate your design notebook entries, failure to follow the lab guidance could adversely affect your Documentation grade.
Purpose
In both hardware and software development, we use a variety of tools to achieve our goals, tools such as compilers, linkers, simulators, etc. These tools can be quite complex, have non-trivial inter-dependencies, and the overall process of invoking all the necessary tools to build the final product may have many steps.
For projects of sufficient complexity, it is rarely feasible and never desirable
to run all the necessary tools by hand. Instead, we write programs to run the
tools for us. These programs are collectively referred to as the
toolchain. In this lab, you will learn to work with the major toolchain
program used by the Processor Design Team, a tool called cmake.1
Part 1: CMake Hello World
cmake is a tool for describing toolchains. Typical usage of cmake looks
like:
cmake [directory]
Where [directory] is a location on the filesystem that contains a file named
CMakeLists.txt. This file is often referred to as an acronym, “CML”, and we will do so in these lab instructions as well.
We will start by creating an empty CMakeLists.txt file in the lab directory.
Before we put any commands into the file, we need to know what version of
cmake we are running. We can discover this with the command:
cmake --version
Make Note: What version of cmake is running in your environment?
The cmake version number is split into three parts, separated by periods. The
first is called the major version, the second the minor version, and the
third is called the patch number. These make up a system known as
semantic versioning which we will discuss more in a later
lab.
Now we are ready to add the first line of code to our CML file, and it should look like this:
cmake_minimum_required(VERSION [major].[minor])
In this line of code, [major] and [minor] should be the major and minor
version number you learned from the earlier command. As you might suspect,
cmake_minimum_required is a cmake command which will ensure the cmake tool
running the file is at least of a minimum version. Unless you’re specifically
testing or making certain your CML runs on older cmake versions, it’s best to
set this to the version of cmake you’re currently using.
The next line of code isn’t strictly necessary for "Hello World", but you will
see it in nearly every CML so we’ll include it here too:
project(week-one-lab VERSION 1.0.0)
Here we have the project name and version number for our code. This isn’t very significant yet, but it will be in the future.
It’s time to make the magic happen, the third line of your CML will be:
message("Hello World")
Now we’re ready to run cmake. First, create a directory named build inside
your lab folder. In a console, navigate to the build directory and run the
command cmake ... The .. tells cmake to look for our CML file in the
parent folder of our current working directory.
cmake will generate an amount of output, but among its many messages should be
our "Hello World"!
Part 2: Building a Program
The astute student will notice that our build directory is now filled with
random crap. This is, in fact, why we created the build directory. In the
future, we’re always going to want to run cmake in its own directory for
this reason, so that the generated files don’t pollute our source code folder.
But what are all these files? What purpose do they serve? Before we answer
that question, let’s try to build an actual program with cmake. First,
write a Hello World program in C++ and save it as hello.cpp at the top
level of the lab repository (the same folder which holds the CML).
Next, we’re going to tell cmake we would like to build a program, using the
following two lines of code. You can remove your message() command from the
CML and replace it with:
add_executable(hello_world)
target_sources(hello_world PRIVATE hello.cpp)
The first line informs cmake about the new program named hello_world that
we would like to create, and the second tells cmake about a source code file
we would like to associate with this new program, and that’s it! (We’re going
to ignore that PRIVATE keyword for now).
Inside the build directory, run the cmake .. command again to re-run the
cmake tool on the edited CML.
Unfortunately, our program has not been created. In fact, the files inside the build directory are exactly the same files as before. Before we answer that question, let’s get a working hello world program. The following command, run inside the build directory, will build the final program:
make
The command is make not cmake
Make Note: Run make help and figure out what the valid targets (command
arguments) are for this project. For all the targets that start with “hello”,
can you figure out what they produce? What about all and clean?
Despite their similar names, make and cmake are completely unrelated
programs. make is a build system, it produces a final program executable that
you can run. cmake is a meta-build system, it reads the CML and produces
other build systems, such as the Makefile that make uses to build our
hello_world program.
Just like a compiler can support multiple computer architectures, cmake
supports multiple build systems. In the build directory, try running the
following commands so that cmake will generate a ninja build system instead
of a make build system (the first command removes the old files from the
build directory, to prevent errors):
rm -rf *
cmake -G Ninja ..
Now you can run the ninja command in the build directory to produce the final
binary. Optionally, you can run cmake --build . and cmake will run the
correct build tool for whichever build system was generated.
Why is this so complicated? Historically, build systems were either fast and
hard to use or very slow but flexible and easy to use. cmake’s solution to
this problem was a flexible tool that generates a fast build system. The ninja
build system in particular is never meant to be used directly by humans, but
only as a target for other programs like cmake.
Part 3: Adding More Files
Now that we have basic cmake usage down, there’s only a little more left to
talk about before you’re ready to strike out on your own.
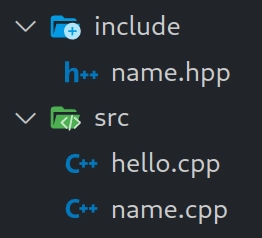
Let’s create a more typical file structure, we’re going to have an src
directory that holds C++ implementation files, and an include directory
that holds C++ header files. We’re also going to create two new files,
name.cpp and name.hpp. The final file structure should look like this:
In name.cpp write a function that asks the user their name, and returns it as
a std::string and add the function declaration to name.hpp. In hello.cpp,
include the header file with #include "name.hpp" and call the associated
function so that you can greet the user by name.
We can modify our target_sources command in the CML to account for the new
file locations:
target_sources(hello_world PRIVATE src/hello.cpp src/name.cpp)
It would also be acceptable to do this across multiple commands:
target_sources(hello_world PRIVATE src/hello.cpp)
target_sources(hello_world PRIVATE src/name.cpp)
Header files do not need to be added directly, instead, we just need to inform the build system what directories to search for them in:
target_include_directories(hello_world PRIVATE include)
You should now be able to build and run your modified hello world program
Answer the following:
-
The paths used by
target_sourcesandtarget_include_directoriesare relative, not absolute. What file or folder are they relative to? -
What are some differences between
cmakeandninja? -
Why is it important to run
cmakein its own directory?
-
You may wonder, “Why do I have to learn this before I’ve written any code?” In programming classes where you only had to run a compiler on a single file, it was fine to just invoke the compiler directly. For hardware design, even the simplest designs will involve running dozens of commands. It would slow you down significantly if you didn’t know how to use the toolchain before moving into the actual design process. ↩